Telestra Software
Telestra 3D Soundfield Reconstruction
Introduction
There are two aspects to the simulation of sound; the fidelity of the sound representation itself, and the accuracy of the recreated soundfield, which is closely related to the directionality of the sounds as perceived by the users of the system. When both of these components come together at the highest level, sound becomes a truly immersive experience. The second part of the sound simulation, the recreated soundfield, has traditionally received scant attention, but this is exactly the problem ASTi has addressed with the introduction of Soundfield Reconstruction (SFRC).
ASTi Soundfield Reconstruction
The heart of the SFRC system is that all sounds generated within the model are encoded in such a manner that the resultant signal “descriptor” contains a full description of the soundfield that the source signal would have generated relative to a reference location (which in our case is the current location of the operators/trainees within our simulated system - perhaps a pilot, or operative on the ground). In some cases, the source soundfield will always remain fixed relative to the reference (perhaps this is the sound of the engines attached to the aircraft), or in other cases will change dynamically (perhaps the sound of another aircraft passing the ownship). In either case, it is the soundfield signal that is encoded, not a set of gains that, by inference, must apply to a fixed configuration of replay channels.
So each individual sound has a soundfield signal descriptor, and just like real sound, the composite of all the individual sounds is the sound heard at the reference location. Once we have the composite soundfield signal descriptor (achieved simply by “mixing” the individual soundfield signal values), we have the signal we want replayed. The decoder takes the soundfield descriptor values and reconstructs the soundfield.
At this stage there is a very nice issue to bring up; the internals of the model and the positional information included within the soundfield signal descriptor values are entirely decoupled from the replay configuration, which makes the model a truly portable entity, at least from the perspective of the replay system. As long as the decoder can support a variable geometry replay system, then nothing within the internals of the model need changing. A good case study for this is the application of the same aircraft sound model to a Full Flight Sim (FFS) and a Flat Panel Training Device (FPTD). In the FFS case, the sound system might use 12 loudspeakers deployed around the device, while the FPTD might use only 2. However, with the application of SFRC technology, the only difference between the two systems is a change to the decoder configuration (2 channels with the speaker relative locations, versus 12 channels and corresponding speaker coordinates).
The SFRC decoder takes the soundfield signal descriptor, and calculates the resultant audio signal output for each replay channel. In order to set-up the decoder all that is necessary is to provide the number of channels and then provide the speaker coordinates (x,y,z relative to the reference position) for each channel as initial configuration settings. An important factor in the accuracy of the localization is that all loudspeakers are used all of the time to generate the soundfield.
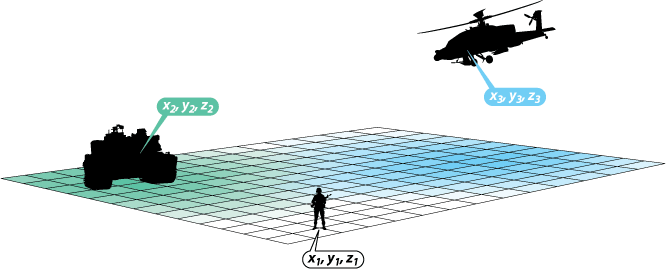
There are some aspects that need to be considered for the replay system, particularly the more regular the speaker array is around the listener, the better the sound localization (since the soundfield will be more convincingly complete), and related to this, in order to provide height information it is necessary to provide speakers with vertical separation. A good starting point is a full cube configuration centered on the reference position (requiring 8 speakers).
Introduction
There are two aspects to the simulation of sound; the fidelity of the sound representation itself, and the accuracy of the recreated soundfield, which is closely related to the directionality of the sounds as perceived by the users of the system. When both of these components come together at the highest level, sound becomes a truly immersive experience. The second part of the sound simulation, the recreated soundfield, has traditionally received scant attention, but this is exactly the problem ASTi has addressed with the introduction of Soundfield Reconstruction (SFRC).
ASTi Soundfield Reconstruction
The heart of the SFRC system is that all sounds generated within the model are encoded in such a manner that the resultant signal “descriptor” contains a full description of the soundfield that the source signal would have generated relative to a reference location (which in our case is the current location of the operators/trainees within our simulated system - perhaps a pilot, or operative on the ground). In some cases, the source soundfield will always remain fixed relative to the reference (perhaps this is the sound of the engines attached to the aircraft), or in other cases will change dynamically (perhaps the sound of another aircraft passing the ownship). In either case, it is the soundfield signal that is encoded, not a set of gains that, by inference, must apply to a fixed configuration of replay channels.
So each individual sound has a soundfield signal descriptor, and just like real sound, the composite of all the individual sounds is the sound heard at the reference location. Once we have the composite soundfield signal descriptor (achieved simply by “mixing” the individual soundfield signal values), we have the signal we want replayed. The decoder takes the soundfield descriptor values and reconstructs the soundfield.
At this stage there is a very nice issue to bring up; the internals of the model and the positional information included within the soundfield signal descriptor values are entirely decoupled from the replay configuration, which makes the model a truly portable entity, at least from the perspective of the replay system. As long as the decoder can support a variable geometry replay system, then nothing within the internals of the model need changing. A good case study for this is the application of the same aircraft sound model to a Full Flight Sim (FFS) and a Flat Panel Training Device (FPTD). In the FFS case, the sound system might use 12 loudspeakers deployed around the device, while the FPTD might use only 2. However, with the application of SFRC technology, the only difference between the two systems is a change to the decoder configuration (2 channels with the speaker relative locations, versus 12 channels and corresponding speaker coordinates).
The SFRC decoder takes the soundfield signal descriptor, and calculates the resultant audio signal output for each replay channel. In order to set-up the decoder all that is necessary is to provide the number of channels and then provide the speaker coordinates (x,y,z relative to the reference position) for each channel as initial configuration settings. An important factor in the accuracy of the localization is that all loudspeakers are used all of the time to generate the soundfield.
There are some aspects that need to be considered for the replay system, particularly the more regular the speaker array is around the listener, the better the sound localization (since the soundfield will be more convincingly complete), and related to this, in order to provide height information it is necessary to provide speakers with vertical separation. A good starting point is a full cube configuration centered on the reference position (requiring 8 speakers).